
This guide was written by a real human, not AI.
If you're looking for an "all you can eat" token plan with predictable hourly costs, connecting OpenCode to a self-hosted vLLM instance on Hot Aisle is a great way to get out of token jail.
Instead of paying per request, you run your own model on dedicated GPUs and let OpenCode interact with it over an API endpoint just like a hosted provider. The difference is that you control the hardware, the cost model, and the data.
Because the model runs on dedicated GPU infrastructure, costs are tied to hardware time rather than per-token usage. This can be helpful during development and experimentation, since iterative workflows such as coding agents often involve many repeated prompts, tool calls, and refinements. When the infrastructure is already running, additional experimentation does not change costs until you scale the hardware itself, which can make it easier to explore configurations and workflows without constantly thinking about token consumption.
In this guide, we'll deploy a VM on Hot Aisle and connect it to OpenCode using vLLM as the inference server. The VM used in this example includes 1 × AMD MI300X GPU with 192 GB of VRAM. For the model, we are using Qwen/Qwen3-Coder-30B-A3B-Instruct, which has been working well for coding workflows. We'll also cover a few important configuration details that matter specifically for coding agents.
What is OpenCode?
OpenCode is an open-source coding agent and developer assistant that connects to language models to help write, modify, and reason about code inside your local development environment. Unlike traditional chat interfaces, OpenCode is designed to interact directly with your project by reading files, editing code, executing commands, and iterating based on results, which makes it especially powerful for real development workflows.
It supports multiple model providers, including self-hosted inference servers like vLLM, allowing you to run coding agents on your own infrastructure instead of relying on hosted APIs. You can learn more about OpenCode and install it from the official site: https://opencode.ai
Hot Aisle + vLLM Basics
New to Hot Aisle or vLLM? Here's what to know before we get started.
Hot Aisle provides access to dedicated GPU infrastructure with predictable hourly pricing, which makes it a great fit for running your own models instead of paying per-token API costs. Instead of sending prompts to a hosted provider, you deploy a virtual machine with GPUs, load a model locally, and expose it through an API endpoint.
vLLM is the component that makes this practical. It is an optimized inference server designed for large language models that focuses on efficient GPU utilization, high throughput, and fast response times. vLLM handles model loading, token generation, batching, and memory management (including KV cache allocation), and exposes an OpenAI-compatible API that tools like OpenCode can connect to directly. In other words, vLLM is the bridge between your GPU hardware and your coding assistant.
In this setup, OpenCode runs locally on your machine while the language model runs remotely on a Hot Aisle GPU VM. The two communicate over a secure SSH tunnel, allowing OpenCode to interact with the remote model just like it would with a hosted API provider.
vLLM runs inside a Docker container on the Hot Aisle VM and exposes an OpenAI-compatible API endpoint that OpenCode connects to. This separation allows you to use powerful remote GPUs while keeping your development workflow local. Running vLLM in Docker simplifies dependency management and makes deployments reproducible, since the ROCm runtime, model libraries, and server configuration are packaged together rather than installed directly on the host operating system.
Essentially, the architecture looks like this:

Now, let's walk through getting started.
Deploying Your VM and Model
Hot Aisle is simple to get started with. You can start with issuing the following command at your terminal:
ssh admin.hotaisle.app
Yes, that's really it. You can find more details at the quick-start guide here.
While you're in the Hot Aisle TUI, we will also need to generate an API token and take note of our team name when we create it, because we will need them to deploy a VM with cloud-init.
Hot Aisle has cloud-init templates here: https://github.com/hotaisle/cloud-init-templates, along with a walk through to get started.
You can find my fork of the cloud-init templates here: https://github.com/vmiss33/cloud-init-templates. You can find the template I used in this example, as well as the other templates I am using for other projects.
The cloud-init file I used is as follows:
#cloud-config
#Get Qwen3 Coder Next running.
runcmd:
- |
echo "Starting vLLM Docker container..."
docker rm -f vllm || true
docker run -d \
--name vllm \
--network=host \
--group-add=video \
--ipc=host \
--cap-add=SYS_PTRACE \
--security-opt seccomp=unconfined \
--privileged \
--device /dev/kfd \
--device /dev/dri \
--restart=always \
rocm/vllm:latest \
vllm serve Qwen/Qwen3-Coder-30B-A3B-Instruct \
--max-model-len 131272 \
--block-size 256 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_xml
- |
echo "vLLM container started. Check status with: docker logs -f vllm"
echo "API should be available on port 8000 (host networking)."
A note on the rocm/vllm:latest image tag
The rocm/vllm:latest image above is the easy default and works for the model in this guide, but it is currently frozen at a December 2025 build (vLLM 0.11.2 / transformers 4.57.3). That means it predates newer model architectures: for example Qwen3.5 / Qwen3.6 (model_type: qwen3_5) fail to load on it with model type qwen3_5 not recognized.
If you are running a current or bleeding-edge model, use the upstream vLLM ROCm image vllm/vllm-openai-rocm:latest instead. Its ENTRYPOINT is already ["vllm", "serve"], so pass serve <model> ... as the container command (drop the leading vllm):
rocm/vllm:latest \ # frozen Dec 2025 — fine here, rejects Qwen3.5/3.6
becomes:
vllm/vllm-openai-rocm:latest \ # tracks upstream vLLM, day-0 new-model support
serve Qwen/Qwen3-Coder-30B-A3B-Instruct \
This was validated on a single MI300X with Qwen3.6-27B in June 2026.
vLLM Configuration Explained
If you are new to vLLM, here are the key configuration parameters to understand:
vllm serve Qwen/Qwen3-Coder-30B-A3B-Instruct \
--max-model-len 131272 \
--block-size 256 \
--enable-auto-tool-choice \
--tool-call-parser qwen3_xml
Max-model-len is the maximum context window that the model is to support. Each model will specify what it's maximum context length is, and you may tweak this value according to your needs. vLLM allocates KV cache based on the context length, and it is important to remember that the KV cache lives in GPU memory. Remember, within our GPUs we need to consider the weight of the model as well as the KV cache size.
Block-size controls how vLLM allocates memory blocks for the KV cache. Larger values can improve efficiency for long contexts, but this can become a sizing/architectural concern based on the number of concurrent users.
Qwen/Qwen3-Coder-30B-A3B is the model we are using. Want to try a different model? This is the line to replace here in your cloud-init file/docker run command, and in the OpenCode configuration.
Enable-auto-tool-choice allows the model to decide when it needs to use tooling.
tool-call-parser qwen3_xml is the tool parser for the qwen3 family of models, there are multiple tool parsers available in vLLM. I have found this one to work best.
Understanding GPU Memory and Concurrency
When running models locally, GPU memory usage is not determined by the model size alone. There are two primary components that consume GPU memory:
- Model weights
- KV cache (context memory)
KV cache stores attention data for every token in the conversation and grows linearly with context length. This means that parameters like --max-model-len directly impact GPU memory usage because vLLM allocates memory for the maximum possible context window.
In this example, I am running on an AMD MI300X GPU, which has 192GB of VRAM. This large memory capacity makes it possible to run larger models and longer contexts comfortably, but the same principles apply on smaller GPUs.
One of the most important concepts to understand is that KV cache does not just affect whether the model fits in memory, it also impacts concurrency. The more memory allocated for context, the fewer simultaneous requests the GPU can handle. Larger context windows increase flexibility for long prompts and coding workflows, but they reduce how many sessions can run in parallel.
This creates a tradeoff between:
- Context length
- Concurrency
- GPU memory usage
Coding agents like OpenCode typically consume context faster than traditional chat workloads because tool outputs, file contents, command results, and iterative reasoning steps are all added back into the prompt. This means context length and KV cache sizing become more important when running agents than when running conversational assistants. In practice, agent workloads often benefit from larger context windows, but this also increases memory usage and reduces concurrency, reinforcing the importance of understanding GPU memory tradeoffs.
For coding agents like OpenCode, longer contexts are often beneficial because tool outputs, file contents, and iterative reasoning can quickly increase token counts. However, understanding how KV cache impacts concurrency becomes important when scaling beyond a single user or running multiple sessions.
Tools like rocm-smi are useful during experimentation to monitor memory allocation and GPU utilization while the model is running.
Tooling in vLLM
The tooling aspect of vLLM is the biggest difference between using OpenCode and using a language model as a simple chatbot.
OpenCode relies heavily on tool calling to function as a coding agent rather than just a text generator. Instead of only producing code suggestions, the model must be able to decide when to interact with the environment, such as reading files from the repository, modifying code, executing commands, running tests, and then inspecting the results before continuing.
This creates an iterative loop where the model alternates between reasoning and taking actions.
The --enable-auto-tool-choice flag allows the model to autonomously decide when a tool should be used during that process rather than requiring the application to force tool usage.
The --tool-call-parser qwen3_xml flag tells vLLM how to interpret the structured tool calls emitted by Qwen3-family models, which use an XML-based format to represent tool invocations. Without the correct parser, vLLM would treat those tool calls as plain text instead of actionable instructions.
Together, these flags enable OpenCode to operate correctly by allowing the model to both decide when tools are needed and communicate those decisions in a format the runtime can execute.
After Building the VM
After issuing the command to build the VM, you will see the following returned in your terminal in a moment or two.
You can call your cloud-init script as follows, illustrated in the Hot Aisle cloud-init repo. I've put the file I used in my fork in this example.
export API_TOKEN="your-api-token-here"
export API_BASE="https://admin.hotaisle.app/api"
export TEAM_SLUG="your-team"
curl -X 'POST' \
"${API_BASE}/teams/${TEAM_SLUG}/virtual_machines/" \
-H 'accept: application/json' \
-H "Authorization: Token ${API_TOKEN}" \
-H 'Content-Type: application/json' \
-d '{
"gpus": [
{
"count": 1,
"manufacturer": "AMD",
"model": "MI300X"
}
],
"user_data_url": "https://raw.githubusercontent.com/vmiss33/cloud-init-templates/master/vllm-docker-qwen3-coder.yaml"
}'
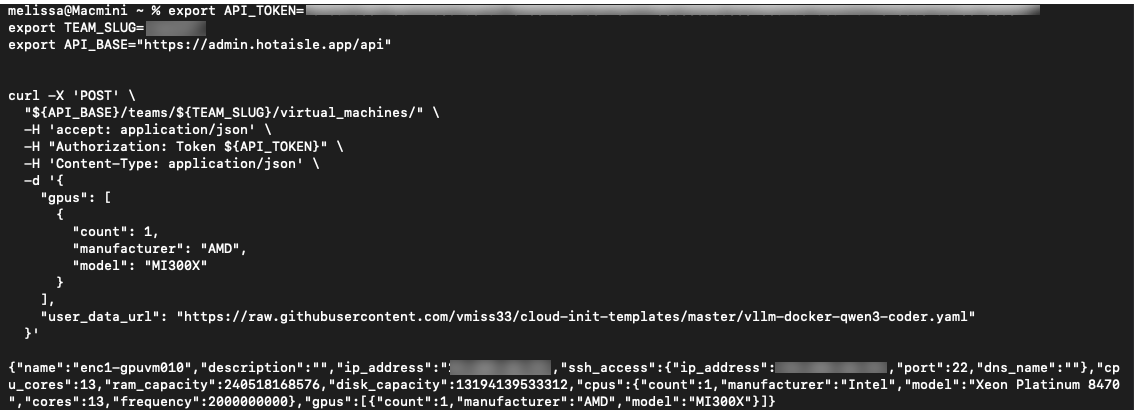
Take note of the IP address of your VM at this step.
Between deploying the VM and starting vLLM, it will take about five minutes. Most of this time is model download and GPU initialization. You can check the status of cloud init with the command:
cloud-init status

Check the status of vLLM with the following command:
docker logs -f vllm
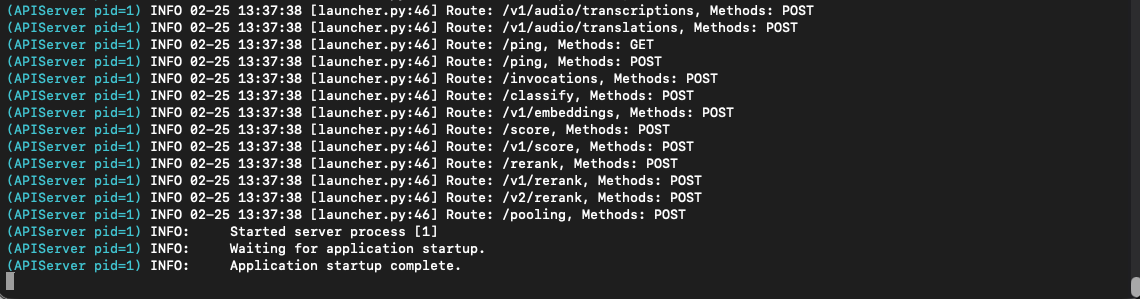
The Application startup complete line indicates the model has completed loading.
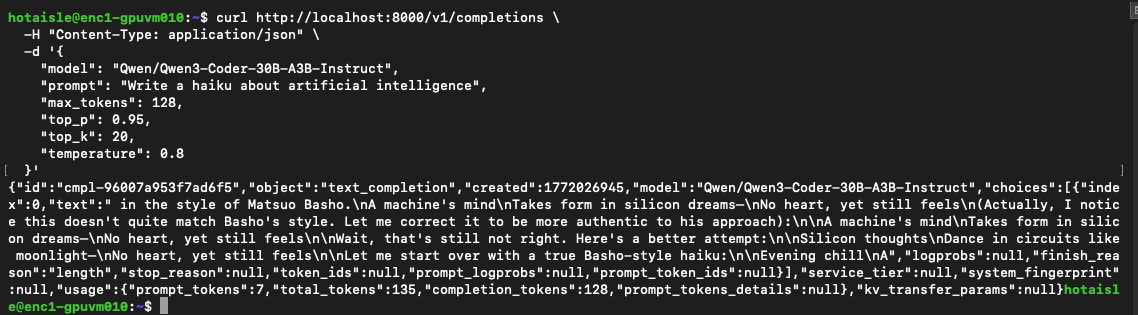
Test the model with the following code:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen3-Coder-30B-A3B-Instruct",
"prompt": "Write a haiku about artificial intelligence",
"max_tokens": 128,
"top_p": 0.95,
"top_k": 20,
"temperature": 0.8
}'
Here's the type of output you are looking for, an entertaining haiku:
Create OpenCode Configuration File
Create a JSON file to serve as the OpenCode configuration file
~/.config/opencode/opencode.json
Here is what mine looks like:
{
"$schema": "https://opencode.ai/config.json",
"provider": {
"vllm-hotaisle": {
"npm": "@ai-sdk/openai-compatible",
"name": "Hot Aisle vLLM (Qwen3 Coder)",
"options": {
"baseURL": "http://localhost:8000/v1",
"apiKey": "sk-no-key-required"
},
"models": {
"Qwen/Qwen3-Coder-30B-A3B-Instruct": {
"name": "Qwen3-Coder 30B A3B Instruct (Primary)",
"limit": {
"context": 131072,
"output": 8192
}
}
}
}
},
"model": "vllm-hotaisle/Qwen/Qwen3-Coder-30B-A3B-Instruct",
"permission": {
"edit": "allow",
"bash": "allow"
}
}
Note: You can only have one model at a time in the file, so if you need to switch modes, don't forget to update the model line of this file.
Create a SSH Tunnel to the Hot Aisle VM
Create a ssh tunnel to the Hot Aisle VM:
ssh -N -L 8000:localhost:8000 hotaisle@x.x.x.x
where x.x.x.x is the IP of your Hot Aisle VM.
Connect to OpenCode
Launch OpenCode, and type /connect, then hit enter.
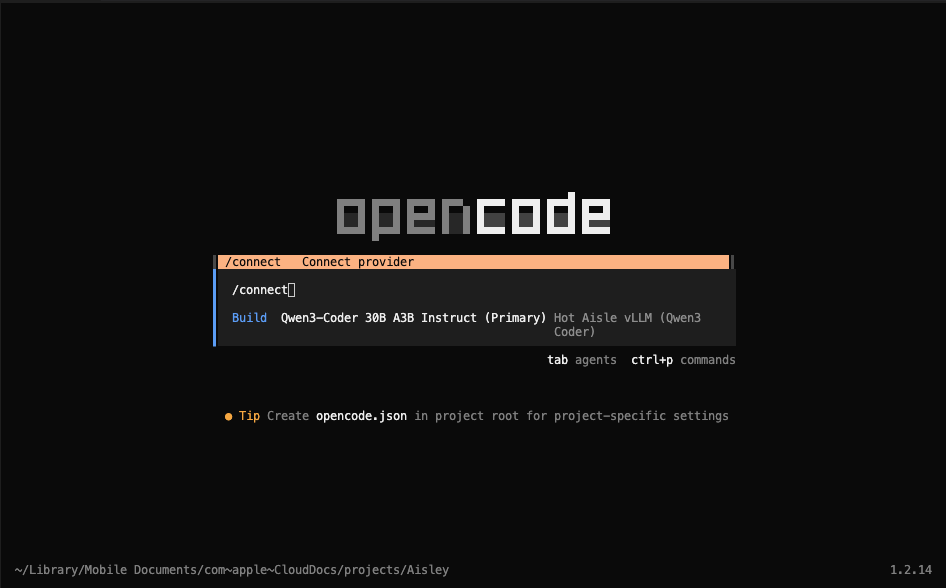
Note: I personally use the OpenCode extension in VS Code.
Scroll all the way down to the bottom and look for "Hot Aisle vLLM (Qwen3 Coder)". This was in our configuration file.
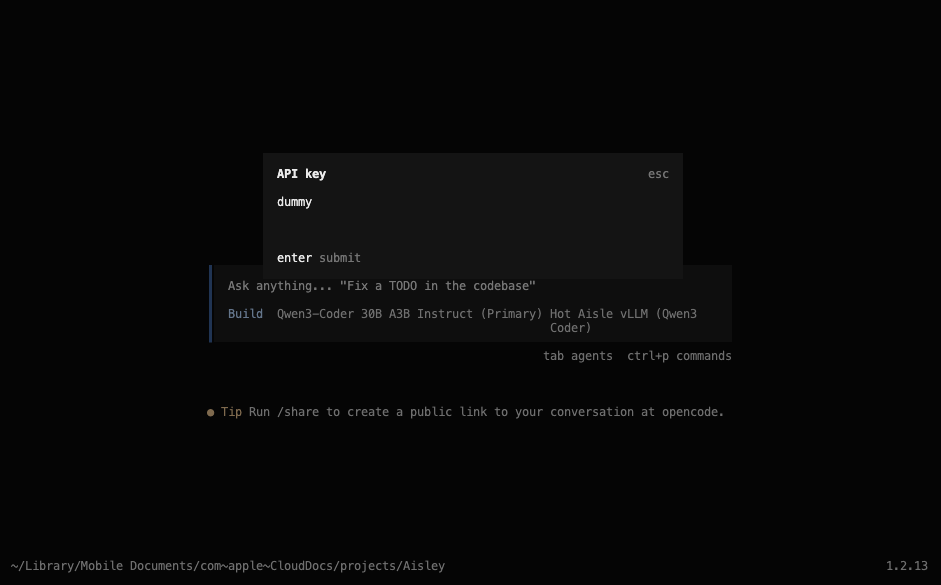
You do not need an API key, so if you are prompted for one just enter some text, I like to use "dummy".
Select the model you wish to use.
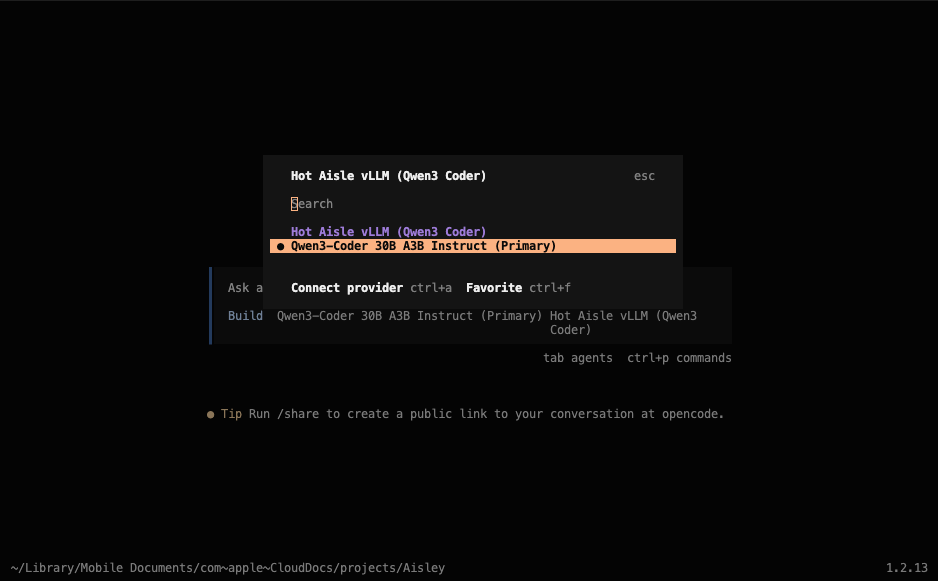
The text Hot Aisle vLLM (Qwen 3 Coder) is the name I gave this provider in the configuration file, and Qwen3-Coder 30B A3B Instruct is the model we are using, which was also specified in the configuration file. You may see different values here based on your setup.
Going forward, OpenCode will remember your selection. OpenCode is now connected to the model and ready to receive prompts.
Other Helpful Hints
Hot Aisle is powered by AMD GPUs and the VM I deployed has 1 x MI300X. This GPU has 192GB of VRAM.
The most useful command to know out of the gate if you are going to experiment with different models is:
rocm-smi
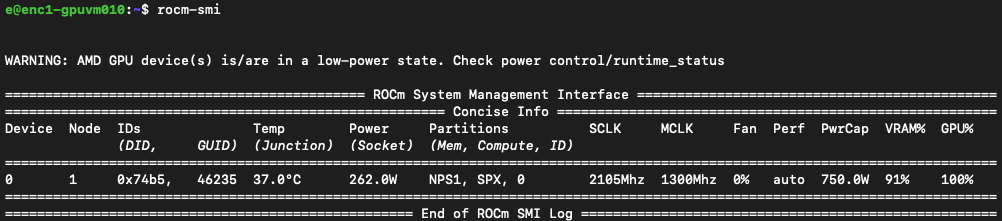
ROCm System Management Interface allows you to monitor your GPU. ROCm or Radeon Open Compute is AMD's GPU software platform. This command is comparable to nvidia-smi if you have used NVIDIA hardware in the past.
Why This Setup Is Powerful
Running OpenCode against a self-hosted vLLM instance changes the development experience significantly. Instead of worrying about token costs or API limits, developers can iterate freely, experiment with different prompts, and run complex agent workflows without friction. This makes remote GPU infrastructure especially valuable for development, research, and prototyping scenarios where experimentation speed matters more than per-request efficiency.
While self-hosting introduces additional infrastructure considerations such as GPU memory sizing and concurrency management, tools like vLLM make it much more accessible than traditional inference stacks. Once configured, the workflow feels very similar to using a hosted provider, but with full control over hardware, data, and configuration.
Useful Links
Here are the main tools and resources used in this guide:
- OpenCode — coding agent: https://github.com/opencode-ai/opencode
- vLLM — inference server: https://github.com/vllm-project/vllm
- Hot Aisle — Simple, hourly GPU infrastructure: https://hotaisle.xyz
- Hot Aisle cloud-init-templates Repo: https://github.com/hotaisle/cloud-init-templates
My Fork of Hot Aisle's cloud-init-templates:
About the Author
This is a guest post from a friend of Hot Aisle. This content is not sponsored or paid.
Melissa Palmeris an infrastructure architect exploring the messy intersection of GPUs, software, and real-world workloads.
- LinkedIn:linkedin.com/in/vmiss
- X:@vmiss33
- GitHub:github.com/vmiss33
Contribute to Hot Aisle
The Hot Aisle website is open source under the MIT License and welcomes contributions from the community. Whether you want to fix a typo, improve documentation, or share your own technical content, we'd love to have your input.
Visit our GitHub repository:github.com/hotaisle/hotaisle-website